Support Archive Search
Live — demo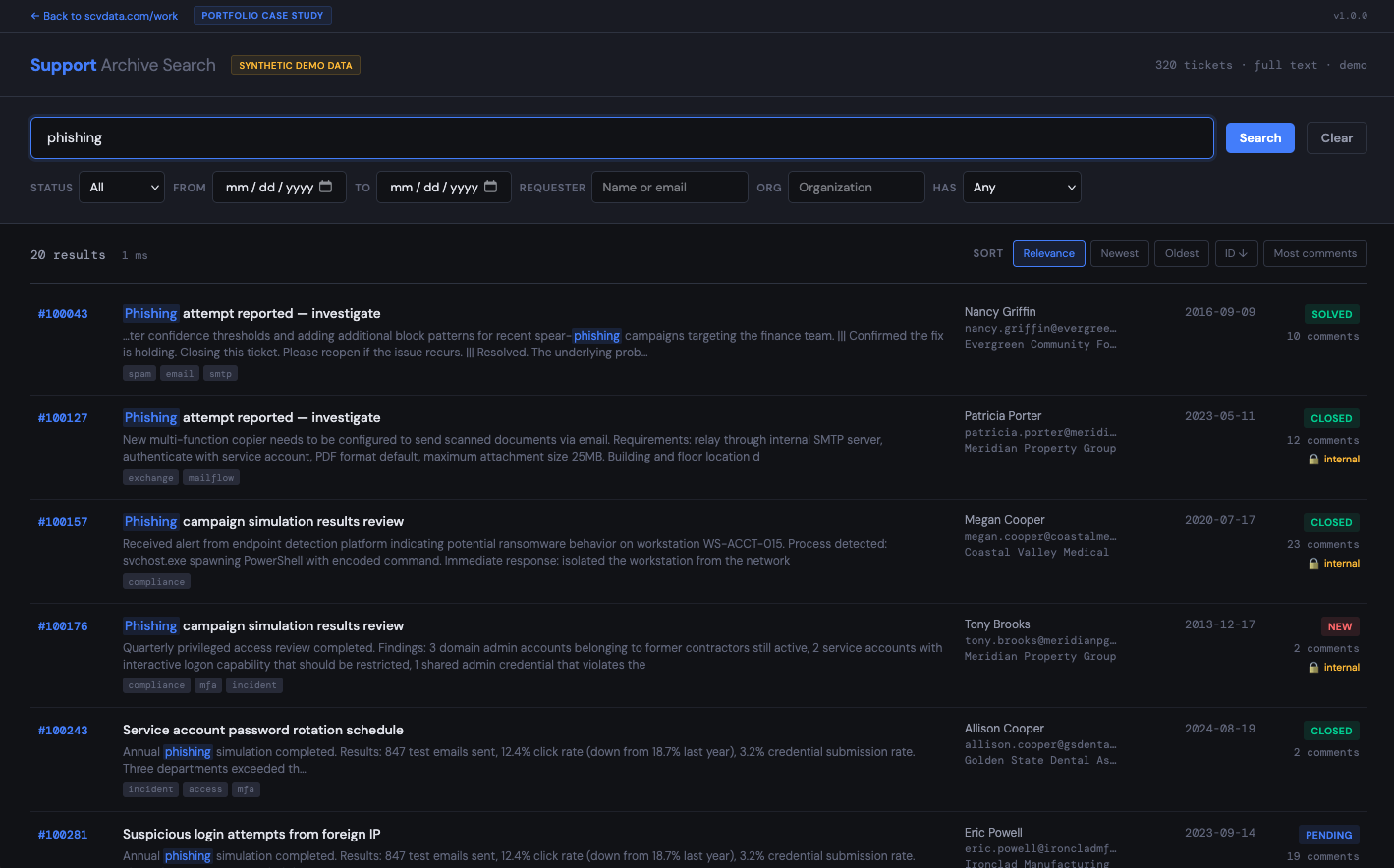
An organization's support history accumulates over years inside its support platform — tickets, comments, resolutions, operational context. As long as that platform remains the active system of record, the archive is reachable through normal support workflows. When the organization migrates off the platform, or when the platform itself is no longer central to operations, that history becomes operationally invisible: the data still exists, but it's no longer findable in the workflows that need it.
For this archive, the data scale was substantial: 31,600 tickets and 130,039 comments spanning the active life of the original support platform. Re-importing all of it into a successor system was neither feasible nor desirable — much of it was historical context, not active work — but the institutional knowledge in those records remained valuable when an operator needed to look something up.
Support Archive Search is a search and retrieval system over the historical support archive. It indexes the full ticket-and-comment corpus and exposes it through a search interface that an operator can use to find prior decisions, resolutions, and operational context without depending on the original support platform being live.
Practical use cases:
- Looking up how a recurring issue was resolved in the past
- Surfacing prior context on a customer or account before a current interaction
- Recovering institutional decisions captured in support exchanges but not documented elsewhere
Before: 31,600 tickets and 130,039 comments of institutional support history existed but were not findable in the workflows that needed them. After: the full archive is searchable, with prior decisions and context one query away.
The system handles the archive as a static dataset: the source platform is no longer the system of record, so the archive doesn't need to update. That simplification — read-only, no live sync, no write path — lets the indexing and retrieval layer be optimized for finding things rather than for managing concurrent writes. The version on search.scvdata.com is a reconstruction using sample ticket data, demonstrating the search interface and the retrieval model without exposing the original archive contents.